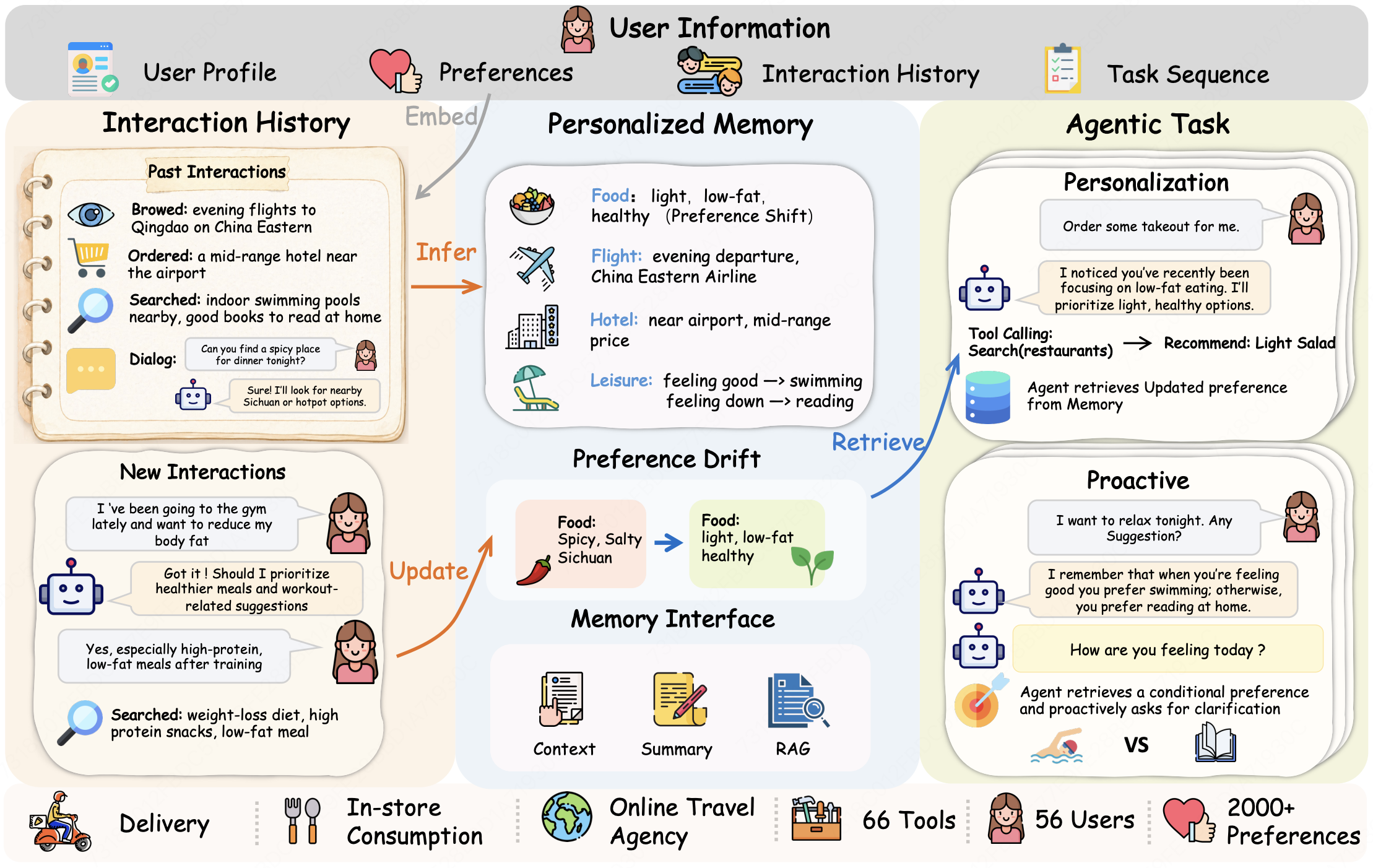
Large language models (LLMs) have evolved into interactive agents that collaborate with users in real-world tasks. Effective collaboration in such settings increasingly depends on understanding the user beyond what is explicitly stated, as user intent is often reflected in fragmented daily interactions and requires both personalized modeling and proactive interaction. However, existing agent benchmarks primarily evaluate reasoning and tool use, largely overlooking the challenges of inferring and leveraging user preferences in realistic scenarios.
To address this gap, we introduce VitaBench 2.0, a benchmark for evaluating personalized and proactive agent behavior in long-term user interactions. Tasks are organized as temporally ordered sequences for individual users, where preferences are embedded in fragmented and heterogeneous interactions. Successful completion of tasks requires the agent to continuously extract, utilize, and update user preferences from these interactions. We further evaluate proactiveness through tasks that require agents to recognize missing information and actively acquire it from users or environments before making decisions. To support systematic analysis, we provide an extensible memory interface that enables controlled comparison across different memory architectures.
We benchmark a diverse set of frontier proprietary and open-source LLMs. Results show that real-world personalization remains highly challenging even for state-of-the-art models, revealing a substantial gap between current capabilities and practical requirements. Extensive analysis further reveals the failure modes and capability bottlenecks of current agents in real-world personalized decision-making, providing insights for future model improvements.
VitaBench 2.0 evaluates personalized and proactive agents through long-term, user-specific task sequences. Rather than treating each task as an isolated prompt, the benchmark places every request within an evolving user trajectory. The agent must rely on interaction histories, memory mechanisms, executable tools, and environment feedback to make decisions that are consistent with the user's preferences and current context. The benchmark is organized around three complementary components. First, each user is associated with a structured profile and a set of fine-grained preferences that are revealed only indirectly through fragmented dialogues and behavior logs. Second, tasks are instantiated in executable service environments, where the user agent interacts with task-specific agents and tools to complete concrete service requests. These tasks are separated by temporal intervals, during which new interaction histories are generated and introduced into the user trajectory, requiring the agent to update its understanding of the user over time. Third, VitaBench 2.0 provides a unified memory interface that separates memory construction from task execution, allowing different memory mechanisms to be compared under the same tasks, tools, and evaluation rubrics. The following sections describe these components and summarize the main capabilities evaluated by the benchmark.
VitaBench 2.0 evaluates four core capabilities required for personalized and proactive agents.
VitaBench 2.0 is a sequential user-agent interaction benchmark. For each user, tasks arrive in temporal order. At each task, a user simulator issues a concrete request, and the agent must fulfill it by interacting with domain-specific tools and an executable environment. Between consecutive tasks, the agent is exposed to newly generated interaction histories that reflect emerging preferences or preference drift. The agent may then update its memory to maintain an evolving representation of the user. This design makes each user trajectory a continuous long-term interaction rather than a collection of independent prompts.
Two design choices make the evaluation better aligned with realistic personalization. First, the user simulator does not directly reveal the underlying preferences. It issues requests from a predefined task list and provides only limited, controlled feedback, preventing agents from shortcutting preference inference through explicit simulator responses. Second, evaluation is rubric-based. Each task is paired with atomic constraints that reflect the user's preferences, such as item attributes, price ranges, temporal conditions, and contextual requirements. These rubrics are applied to both the agent trajectory and the final outcome, allowing VitaBench 2.0 to evaluate not only whether the final decision is correct, but also whether the agent follows a preference-consistent and information-seeking interaction process.
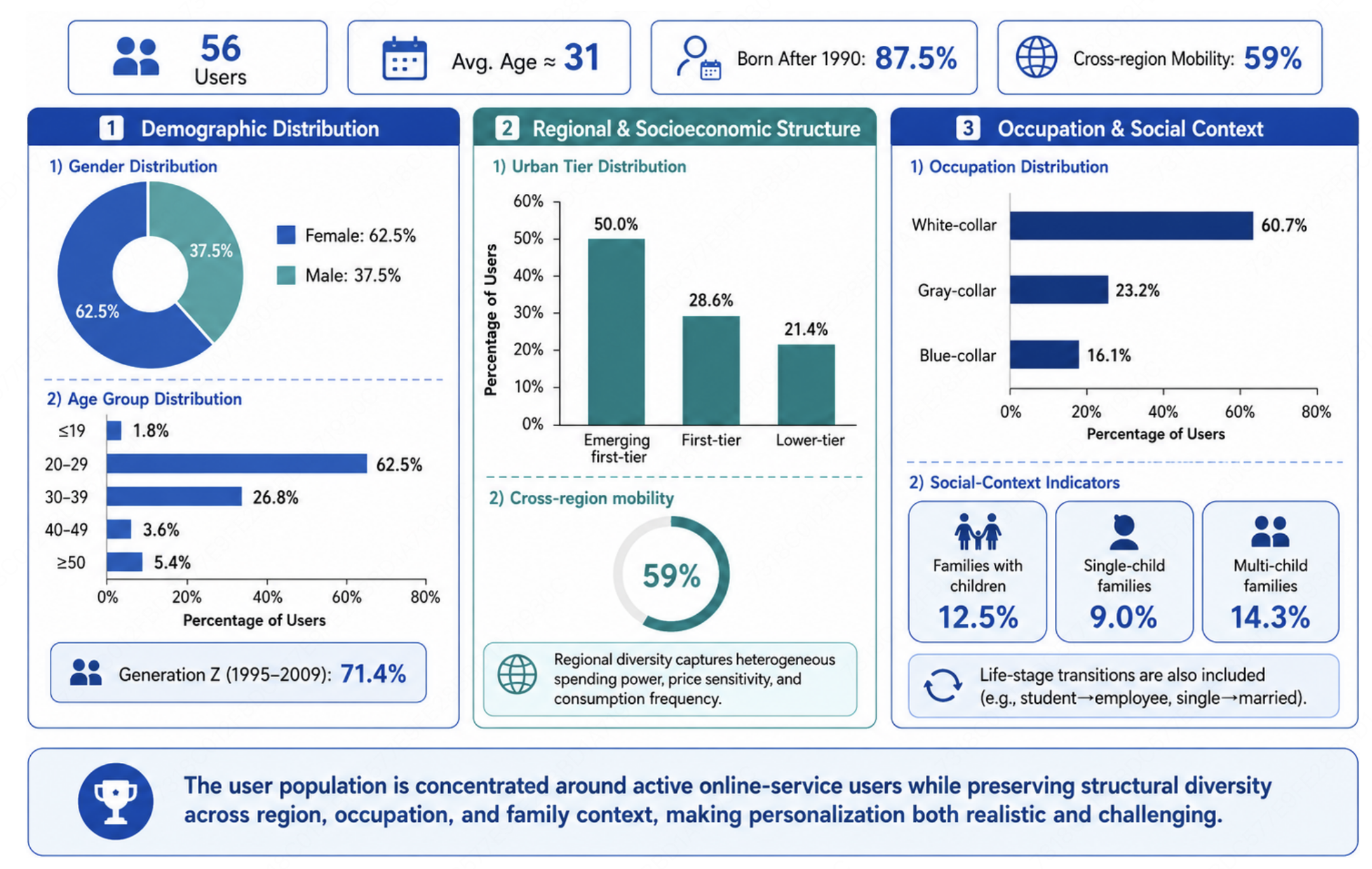
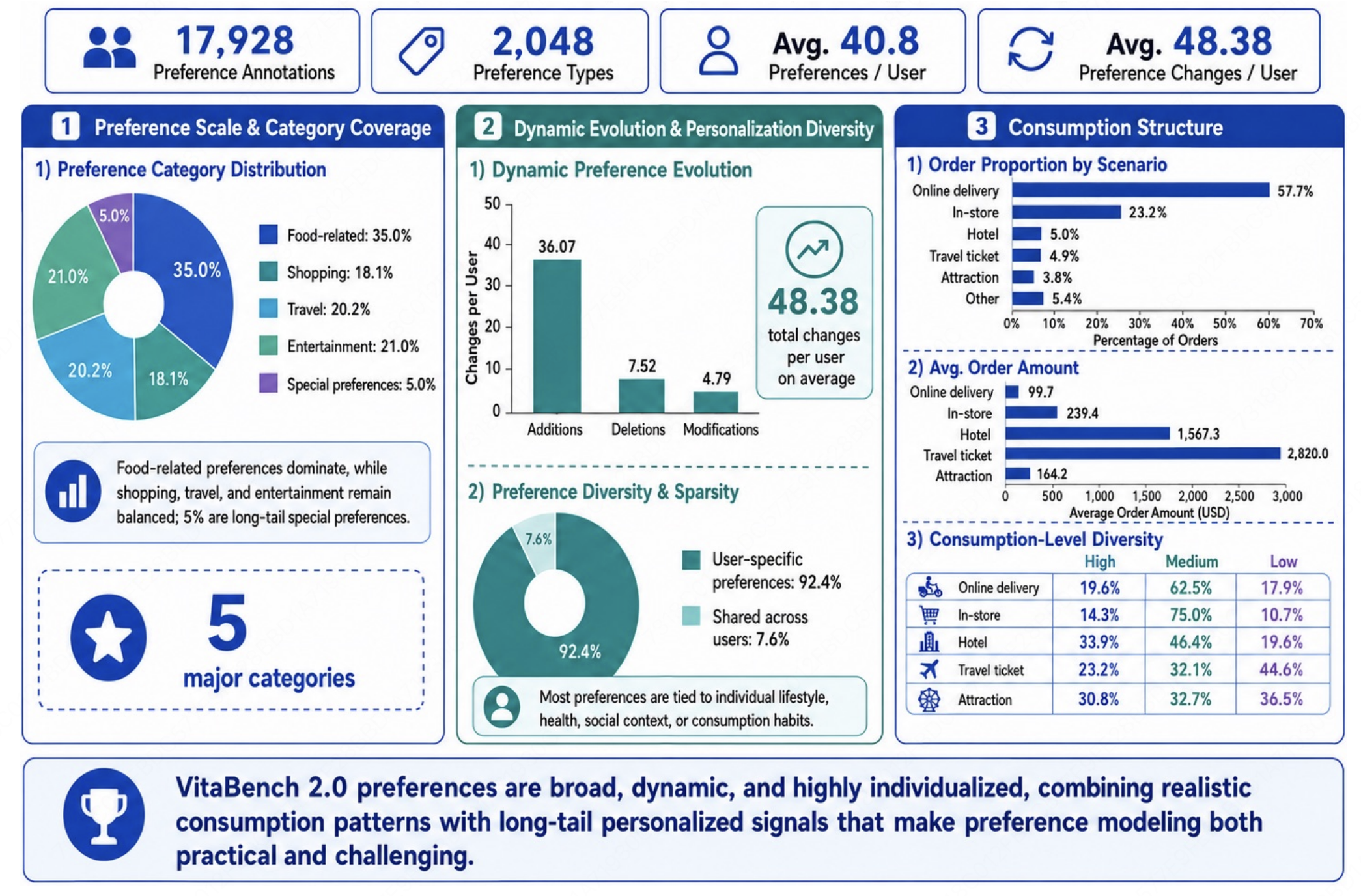
VitaBench 2.0 contains 56 users with carefully constructed profiles and more than 2,000 fine-grained preferences. User profiles cover diverse demographic, geographic, occupational, family, and lifestyle characteristics, while the preference set spans dining, travel, lodging, time, budget, leisure, shopping, and conditional preferences. Each user is associated with a temporally ordered sequence of 10-20 tasks, resulting in 819 subtasks across three real-life service domains: Delivery, In-store Consumption, and Online Travel Agency. These tasks are supported by 66 executable tools.
Preferences are not directly exposed to the agent. Instead, they are embedded in fragmented interaction histories consisting of dialogues and behavior logs, such as browsing, ordering, reviewing, and searching records. These histories contain both preference-relevant signals and noisy interactions that are irrelevant, ambiguous, or context-dependent. This setting requires agents to distinguish stable user preferences from incidental behaviors. To simulate long-term user dynamics, VitaBench 2.0 further introduces temporally grounded preference drift, where preferences may be added, deleted, or modified across the user's task sequence. Each task is paired with atomic rubrics that verify the final environment state rather than only the generated text.
To systematically study the role of memory in personalization, VitaBench 2.0 defines an extensible memory interface with two operations: UPDATE(M, H) integrates newly observed interaction histories into the user's memory, while RETRIEVE(M, q) returns task-relevant information for the current query. When memory is enabled, the agent does not directly access the full interaction history during task execution. Instead, it must rely on the information returned by the memory module. This interface allows different memory architectures to be plugged into the same tasks, tools, and rubrics, enabling controlled comparison.
UPDATE indexes new records, and RETRIEVE performs similarity-based lookup for the current query. This provides a strong retrieval-based baseline, but it does not explicitly control which information should be retained or how conflicting preferences should be resolved. Performance under three memory settings, sorted by Avg@4 on Full Context. Bold = best in column.
| # | Model | Full Context | Agentic Memory | RAG Memory | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Avg@4 | Pass@4 | Pass^4 | Avg@4 | Pass@4 | Pass^4 | Avg@4 | Pass@4 | Pass^4 | ||
| 1 | Claude-Opus-4.6 | 0.503 | 0.664 | 0.337 | 0.454 | 0.645 | 0.259 | 0.430 | 0.566 | 0.299 |
| 2 | Doubao-Seed-2.0-pro | 0.474 | 0.683 | 0.270 | 0.428 | 0.650 | 0.225 | 0.339 | 0.496 | 0.205 |
| 3 | DeepSeek-V4-Pro | 0.472 | 0.649 | 0.295 | 0.449 | 0.656 | 0.255 | 0.430 | 0.584 | 0.271 |
| 4 | GPT-5 | 0.441 | 0.658 | 0.226 | 0.421 | 0.647 | 0.204 | 0.410 | 0.591 | 0.236 |
| 5 | Claude-4.5-Sonnet | 0.417 | 0.658 | 0.197 | 0.397 | 0.642 | 0.178 | 0.374 | 0.573 | 0.186 |
| 6 | o3 | 0.403 | 0.653 | 0.169 | 0.401 | 0.669 | 0.154 | 0.362 | 0.587 | 0.158 |
| 7 | DeepSeek-R1-0528 | 0.396 | 0.691 | 0.131 | 0.412 | 0.712 | 0.118 | 0.390 | 0.643 | 0.153 |
| 8 | GLM-5.1 | 0.394 | 0.587 | 0.213 | 0.352 | 0.556 | 0.150 | 0.328 | 0.485 | 0.185 |
| 9 | Doubao-Seed-1.6 | 0.373 | 0.599 | 0.176 | 0.383 | 0.646 | 0.123 | 0.375 | 0.591 | 0.179 |
| 10 | GLM-4.5 | 0.364 | 0.623 | 0.156 | 0.311 | 0.596 | 0.106 | 0.336 | 0.555 | 0.147 |
| 11 | GLM-4.6 | 0.359 | 0.612 | 0.116 | 0.351 | 0.625 | 0.107 | 0.336 | 0.574 | 0.135 |
| 12 | MiniMax-M2.7 | 0.345 | 0.584 | 0.145 | 0.351 | 0.609 | 0.124 | 0.314 | 0.518 | 0.143 |
| 13 | Gemini-2.5-Pro | 0.331 | 0.605 | 0.109 | 0.378 | 0.638 | 0.138 | 0.320 | 0.579 | 0.109 |
| 14 | Kimi-K2.6 | 0.293 | 0.533 | 0.099 | 0.280 | 0.508 | 0.088 | 0.303 | 0.511 | 0.118 |
| 15 | Qwen3-Max | 0.284 | 0.499 | 0.105 | 0.324 | 0.599 | 0.091 | 0.315 | 0.519 | 0.134 |
| 16 | Gemini-2.5-Flash | 0.282 | 0.556 | 0.063 | 0.312 | 0.567 | 0.098 | 0.309 | 0.544 | 0.107 |
| 17 | o4-mini | 0.210 | 0.433 | 0.047 | 0.270 | 0.533 | 0.073 | 0.261 | 0.452 | 0.091 |
| # | Model | Full Context | Agentic Memory | RAG Memory | ||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Avg@4 | Pass@4 | Pass^4 | Avg@4 | Pass@4 | Pass^4 | Avg@4 | Pass@4 | Pass^4 | ||
| 1 | DeepSeek-V4-Pro | 0.456 | 0.652 | 0.267 | 0.427 | 0.658 | 0.207 | 0.424 | 0.618 | 0.247 |
| 2 | Doubao-Seed-2.0-pro | 0.428 | 0.649 | 0.218 | 0.426 | 0.665 | 0.198 | 0.406 | 0.625 | 0.208 |
| 3 | GLM-5.1 | 0.420 | 0.654 | 0.204 | 0.423 | 0.664 | 0.182 | 0.383 | 0.585 | 0.200 |
| 4 | Kimi-K2.6 | 0.378 | 0.632 | 0.147 | 0.397 | 0.674 | 0.145 | 0.383 | 0.621 | 0.163 |
| 5 | GLM-4.6 | 0.342 | 0.612 | 0.113 | 0.336 | 0.623 | 0.084 | 0.317 | 0.555 | 0.123 |
| 6 | Doubao-Seed-1.6 | 0.326 | 0.512 | 0.171 | 0.340 | 0.576 | 0.129 | 0.351 | 0.543 | 0.174 |
| 7 | GLM-4.5 | 0.307 | 0.529 | 0.127 | 0.330 | 0.569 | 0.112 | 0.316 | 0.523 | 0.152 |
| 8 | LongCat-Flash-Chat | 0.298 | 0.510 | 0.123 | 0.302 | 0.537 | 0.105 | 0.290 | 0.471 | 0.136 |
| 9 | GPT-3.5-Turbo | 0.140 | 0.314 | 0.019 | 0.231 | 0.467 | 0.056 | 0.205 | 0.409 | 0.059 |
| 10 | GPT-4o-mini | 0.067 | 0.180 | 0.006 | 0.084 | 0.229 | 0.008 | 0.094 | 0.227 | 0.011 |
Each result is the average over four independent runs, evaluated with
gpt-4.1-2025-04-14 as user simulator and rubric judge.
Last update: May 2026
Even under the Full Context setting, where agents have access to the complete interaction history, the best-performing models achieve only moderate scores. This suggests that current agents still struggle to identify, prioritize, and apply user preferences in long, noisy, and evolving interaction histories.
Although external memory is essential for long-term user modeling, existing memory mechanisms do not always translate stored user information into better task performance. Agentic Memory may lose or distort information during memory updates, while RAG Memory may retrieve surface-level matches that are not truly relevant to the current decision.
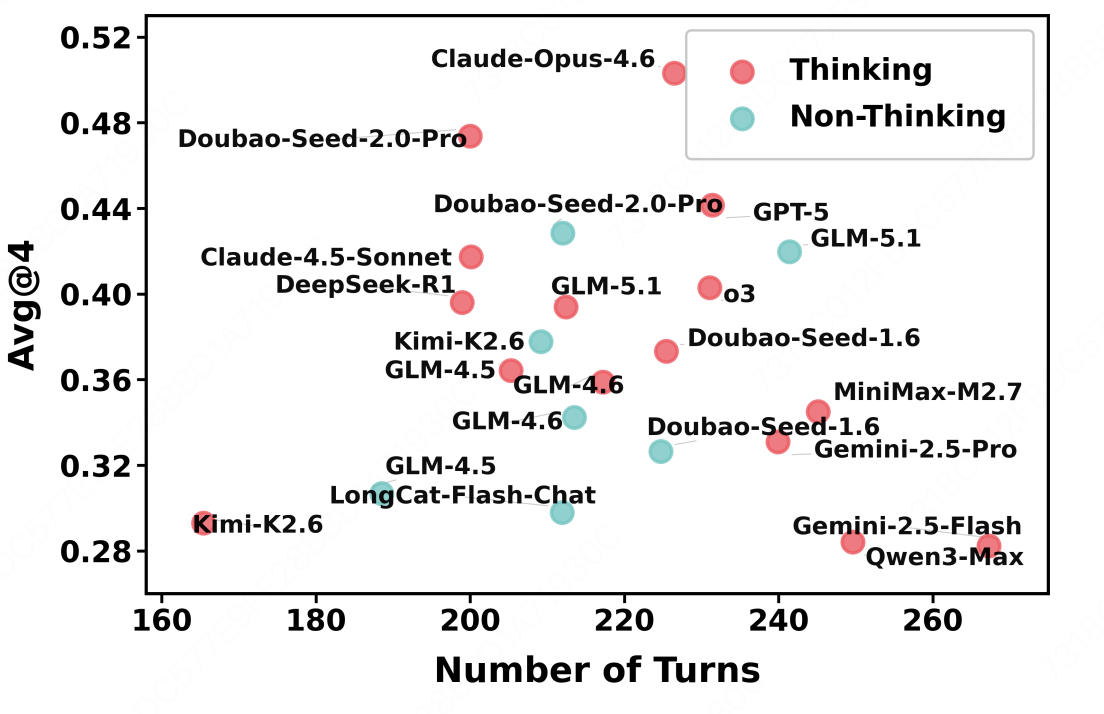
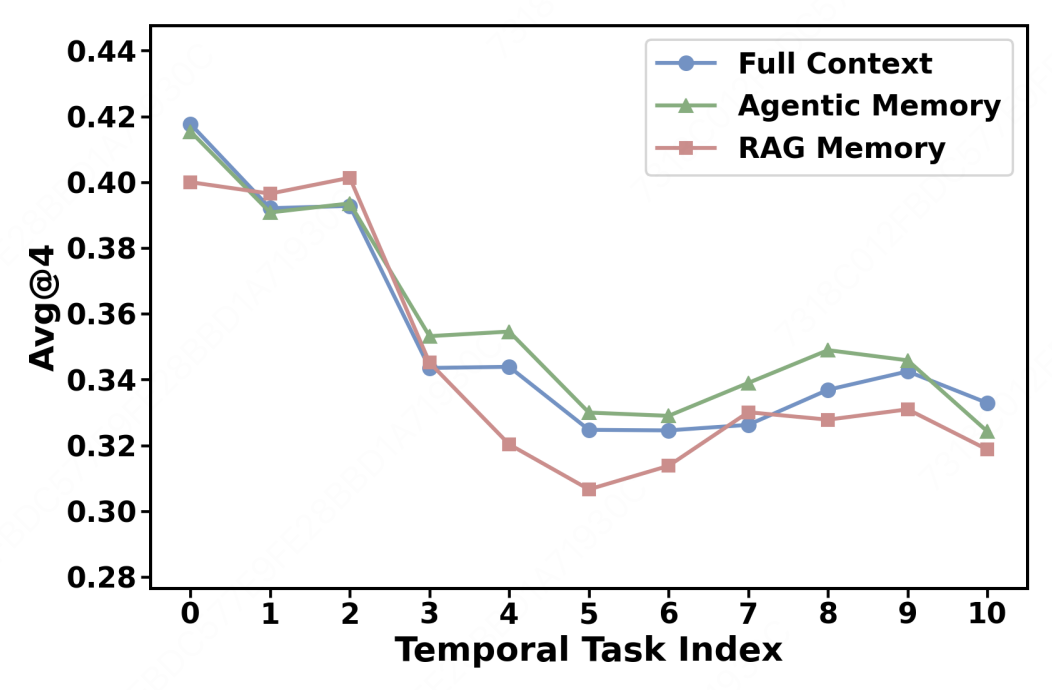
Figure 4 shows that thinking and non-thinking models occupy overlapping regions on both performance (Avg@4) and efficiency (number of turns), with no consistent advantage from enabling thinking mode. This indicates that personalization requires capabilities beyond step-by-step reasoning, including preference extraction, noise filtering, drift handling, and recognition of missing information.
Figure 5 shows that average performance declines as the user trajectory progresses, under all three memory settings. As interaction histories become longer, preferences evolve, and memory errors accumulate, agents face increasing difficulty in maintaining a consistent and up-to-date understanding of the user.
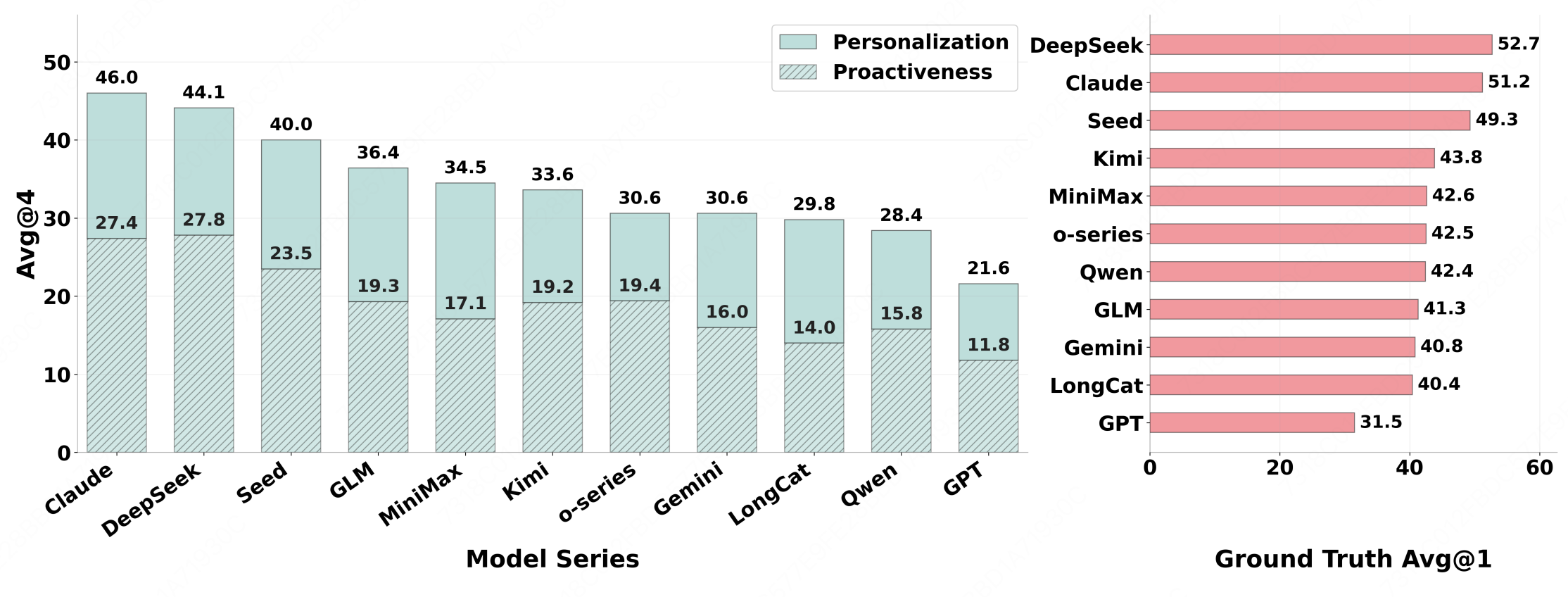
The left panel of Figure 6 shows that proactive task performance consistently trails personalization performance across model families. Agents often fail to recognize when the current query and memory are insufficient, leading them to make premature decisions instead of asking clarifying questions or seeking additional context.
The right panel of Figure 6 shows that even when ground-truth user preferences are provided, top models still reach only moderate performance. This suggests that the main challenge is not only extracting preferences from history, but also correctly ranking, combining, and applying them across multi-step tool-based decisions.
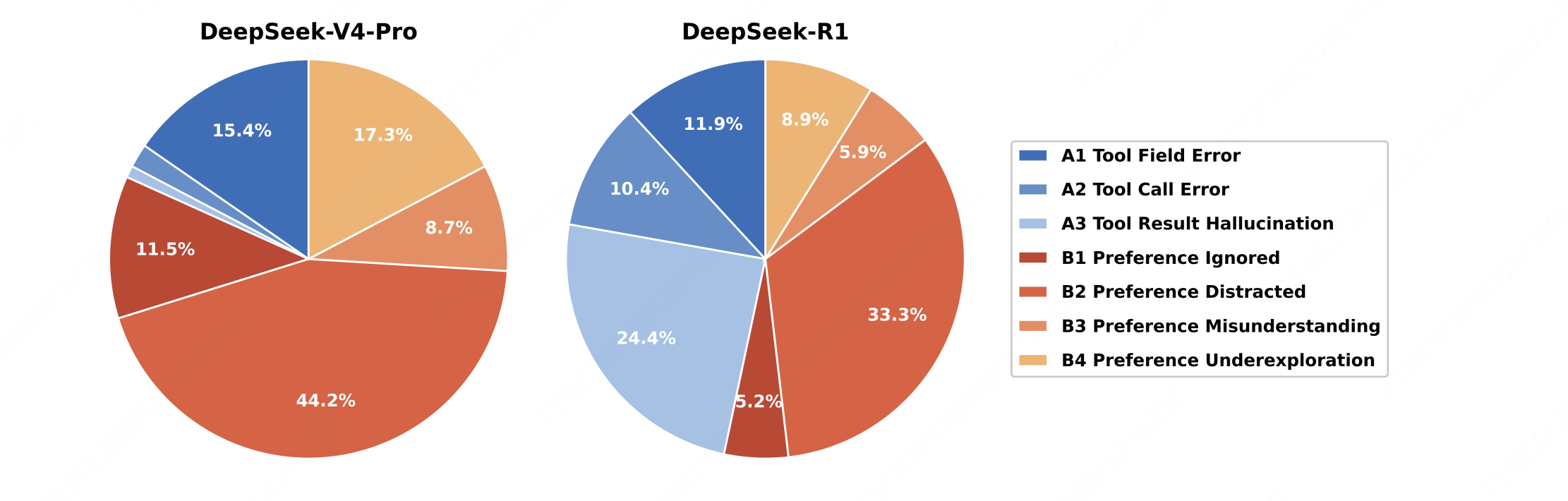
Figure 7 shows that as model capability advances from DeepSeek-R1 to DeepSeek-V4-Pro, tool-related errors (A1–A3) shrink while preference-related errors (B1–B4) grow to dominate. This points to a clear shift: basic tool invocation is no longer the limiting factor for stronger models — instead, capturing, prioritizing and applying user preferences is what frontier models still cannot reliably do, suggesting that future progress on real-world assistants depends more on personalization capability than on raw tool-use proficiency.
@article{chen2026vitabench,
title = {VitaBench 2.0: Evaluating Personalized and Proactive Agents
in Long-Term User Interactions},
author = {Chen, Yuxin and Zhang, Yi and Cai, Zhengzhou and Shi, Yaorui
and Yao, Zhiyuan and Cui, Chenhang and Zheng, Jingnan
and Huo, Yaqi and Su, Xi and Gu, Qi and Cai, Xunliang
and Wang, Xiang and Zhang, An and Chua, Tat-Seng},
journal = {arXiv preprint arXiv:2605.27141},
year = {2026}
}